MT-Disciplined - decoupling thread safety
https://raf.org/papers/mt-disciplined.htmlraf <raf@raf.org>
Abstract
Software libraries often suffer reusability problems in the context of thread synchronisation. Libraries are usually either Unsafe and hence can't easily be used well in a multi threaded application or they are Safe or MT-Safe and use a hard coded synchronisation strategy and hence aren't appropriate for all possible client applications. This paper presents a new MT-Level, called MT-Disciplined, in which synchronisation strategies are decoupled from library code to enhance flexibility and reusability.
Introduction
Software libraries can be classified as either Unsafe, Safe or MT-Safe for the purposes of multi threaded applications. Unsafe means that the library code cannot be executed by multiple threads at the same time unless the application implementer adds synchronisation code when calling the library's functions. Safe means that the library code can be executed by multiple threads but there is no concurrency. The synchronisation built in to the library is no better than if the application implementer had been forced to add it externally. MT-Safe means that the library has been designed to be usable by multiple threads so there is a greater degree of concurrency.
Libraries need to be MT-Safe when used in multi threaded applications. However, most programs are single threaded and synchronisation doesn't come for free so libraries should be Unsafe when used in single threaded applications. Even in multi threaded applications, some objects may only be accessed by a single thread and so should not incur the cost of synchronisation.
When an object is shared between multiple threads which need to be synchronised, the synchronisation strategy must be carefully selected by the application implementer. There are tradeoffs between concurrency and overhead. The greater the concurrency, the greater the overhead. More locks give greater concurrency but have greater overhead. Readers/Writer locks can give greater concurrency than mutex locks but have greater overhead. One lock for each object may be required, or one lock for all (or a set of) objects may be more appropriate.
Generally, the best synchronisation strategy for a given application can only be determined by benchmarking the application itself. It is necessary to be able to experiment with alternative synchronisation strategies while developing the client application in order to achieve the best results. It may even be beneficial to allow the application user to specify synchronisation strategies at runtime if the nature of the data can affect the suitability of the default synchronisation strategy. Unfortunately, most MT-Safe libraries use a hard coded synchronisation strategy thus precluding any experimentation of this sort. The solution presented in this paper is to employ the discipline and method architecture [Vo 2000] by decoupling the synchronisation strategies from the library code.
Traditional Approach
It is common practice for MT-Safe library implementers to hard code a synchronisation strategy into their libraries and then to provide the ability to compile two separate versions by conditionally compiling the synchronisation code [Mattis 1995]. The result is an MT-Safe version for use in multi threaded applications and an Unsafe version for use in single threaded applications. The fact that two separate libraries are required is a clear indication of the lack of reusability of the library.
This approach does produce the fastest code possible for single threaded applications. This is important since most applications are single threaded. However problems still remain for multi threaded applications. They are forced to use the synchronisation strategy hard coded into the MT-Safe version whether it is appropriate for the application or not.
Another problem is that since the two versions of the library will have functions with the same names, it is difficult for multi threaded applications to use functions from both libraries at the same time. This prevents application implementers from using the MT-Safe functions when dealing with objects that are accessed by multiple threads while using Unsafe functions when dealing with objects of the same type that are only accessed by a single thread. If only a few objects are accessed by multiple threads this results in unnecessary overhead.
[Mattis 1995] does decouple the implementation of it's hard coded synchronisation strategy but only for the purpose of porting to the underlying thread libraries of different systems. The effect is just an extra function call per operation. No added flexibility is given to the application implementer.
MT-Disciplined Approach
The MT-Disciplined approach involves decoupling the synchronisation strategy from library code by using a pointer to a synchronisation variable (i.e. a mutex lock or readers/writer lock) and testing that this pointer is not null before calling the functions that manipulate the synchronisation variable. If the pointer is null, the code is Unsafe. If it points to a lock variable, the code is either Safe or MT-Safe, depending on the number of locks used.
The functions that manipulate the lock are invoked indirectly through pointers. This enables the lock pointer to point to either a mutex lock or a readers/writer lock if the function pointers point to the appropriate set of functions. This enables the client application to specify which type of synchronisation variable to use. The client application can also specify whether or not different objects share the same locks.
These elements allow application implementers, and even end users, to specify the synchronisation strategy to apply to library code. A general purpose synchronisation strategy object can be implemented as follows [raf 2000]:
typedef struct Locker Locker;
typedef int lockerf_t(void *lock);
struct Locker
{
void *lock;
lockerf_t *tryrdlock;
lockerf_t *rdlock;
lockerf_t *trywrlock;
lockerf_t *wrlock;
lockerf_t *unlock;
};
#define locker_tryrdlock(locker) ((locker) ? (locker)->tryrdlock((locker)->lock) : 0)
#define locker_rdlock(locker) ((locker) ? (locker)->rdlock((locker)->lock) : 0)
#define locker_trywrlock(locker) ((locker) ? (locker)->trywrlock((locker)->lock) : 0)
#define locker_wrlock(locker) ((locker) ? (locker)->wrlock((locker)->lock) : 0)
#define locker_unlock(locker) ((locker) ? (locker)->unlock((locker)->lock) : 0)
Locker *locker_create_mutex(pthread_mutex_t *mutex)
{
Locker *locker;
if (!(locker = malloc(sizeof(Locker))))
return NULL;
locker->lock = mutex;
locker->tryrdlock = (lockerf_t *)pthread_mutex_trylock;
locker->rdlock = (lockerf_t *)pthread_mutex_lock;
locker->trywrlock = (lockerf_t *)pthread_mutex_trylock;
locker->wrlock = (lockerf_t *)pthread_mutex_lock;
locker->unlock = (lockerf_t *)pthread_mutex_unlock;
return locker;
}
Locker *locker_create_rwlock(pthread_rwlock_t *rwlock)
{
Locker *locker;
if (!(locker = malloc(sizeof(Locker))))
return NULL;
locker->lock = rwlock;
locker->tryrdlock = (lockerf_t *)pthread_rwlock_tryrdlock;
locker->rdlock = (lockerf_t *)pthread_rwlock_rdlock;
locker->trywrlock = (lockerf_t *)pthread_rwlock_trywrlock;
locker->wrlock = (lockerf_t *)pthread_rwlock_wrlock;
locker->unlock = (lockerf_t *)pthread_rwlock_unlock;
return locker;
}
void locker_release(Locker *locker)
{
free(locker);
}
All that is required for a library to be MT-Disciplined is that it use locker objects to manage synchronisation and that it allow the client to supply the locker objects to be used. The simplest way to achieve this is to make every function take a locker parameter. A simpler interface can be achieved in an object oriented library by having each object contain a pointer to a locker whose value is supplied by the client when each object is constructed. This method, however, can suffer from granularity problems which are discussed in the next section. These problems can be solved but it takes more effort on the part of the library implementer.
Either method provides extreme flexibility. Not only can a single library be Unsafe, Safe or MT-Safe, as required, combinations of the above behaviours can exist within the same application. Consider a library that provides a type and functions that operate on objects of that type. If an application uses many of these objects but only one of them is accessed by multiple threads, then the application can supply a locker object to synchronise access to the shared object and supply null locker pointers for all of the non-shared objects.
If multiple objects are accessed by multiple threads, they can share the same locker or each use their own locker. They can even use a different type of locker (i.e. some use mutex locks, others use readers/writer locks). It is also possible to use debugging locker objects that output messages before and after each locking operation to locate deadlocks.
To achieve this functionality using the traditional approach would involve compiling many different libraries (i.e. Unsafe, MT-Safe using mutex locks, MT-Safe using readers/writer locks, MT-Safe using debugging mutex locks, MT-Safe using debugging readers/writer locks). Then some mechanism for distinguishing between functions of the same name in different versions of the library (i.e. wrapper libraries that alter the names and multiple sets of header files). This is clearly difficult to achieve, complex to use, and highly non-scalable.
Granularity
As noted in the previous section, storing a locker object inside an arbitrary object, rather than passing both the locker and the object to each library function, can result in granularity problems. The reason is that hiding the locker inside the object fixes the granularity of synchronisation at the level of a single function call. An application may need to lock an object and then call multiple library functions involving that object before unlocking it.
If recursive locks are available, threads can protect multiple function calls between lock and unlock operations and each function can still perform its own synchronisation without causing deadlock. However, this incurs unnecessary overhead since the underlying thread functions are called more often than is strictly necessary. Also, recursive locks may not be available on all systems.
If the library functions all take a locker parameter, the granularity is controlled by the client. The client can explicitly claim a lock. The library functions can then be called with null locker pointers to prevent them from performing synchronisation themselves. Finally, the client can explicitly unlock the object.
locker_wrlock(locker);
mutate_step1(obj, NULL);
mutate_step2(obj, NULL);
mutate_step3(obj, NULL);
locker_unlock(locker);
If the locker is hidden inside an object that is passed as a parameter, then the library must provide functions to explicitly lock and unlock the object, and it must provide an alternate version of each function that does not perform any synchronisation.
obj_lock(obj);
mutate_step1_unlocked(obj);
mutate_step1_unlocked(obj);
mutate_step1_unlocked(obj);
obj_unlock(obj);
Providing the unlocked version of each function is tedious but achievable. It also produces faster code and presents an interface to the client that is arguably easier to use and easier to read.
Depending on the nature of the library, this may not be an issue. If the library provides all necessary atomic operations and it doesn't make sense for the client to build new atomic operations out of those provided by the library, then there are no granularity problems to deal with.
Performance
While reductions in overhead can be achieved with the ability to only synchronise those objects that require it rather than synchronising all objects of a given library, the flexibility that enables this obviously incurs its own overhead. To determine the overhead, an experiment was performed in which data was accessed using various MT levels: Unsafe, MT-Safe and several different MT-Disciplined implementations. The different methods examined were:
| Methods | ||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
|
The source code for these experiments can be found in the locker module test suite in [raf 2000].
Each method was timed by averaging the time taken to access data ten million times each for no locking, mutex locking and read locking. The experiments were performed at various optimisation levels on three different hosts:
| Architectures | ||||||
|---|---|---|---|---|---|---|
|
Note that the timings for the Unsafe method when optimised are unusable because the compiler moves the data access outside the loop (leaving an empty loop behind) so these timings actually reflect the time taken to perform a single data access followed by ten million iterations of an empty loop.
So, in order to compare Unsafe code with MT-Disciplined
code that performs no locking, we can only consider the unoptimised timings.
To compare MT-Safe code with MT-Disciplined code that
performs equivalent locking, any optimisation level is valid. For the
purposes of discussion, we consider the times obtained from compiling with
gcc -O3 on each of the platforms. All times are measured in
nanoseconds.
| Figure 1 - No Locking |
|---|
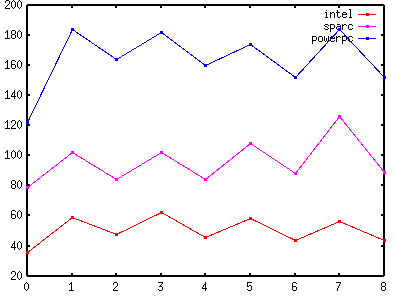 |
| Table 1 - No Locking | ||||||||
|---|---|---|---|---|---|---|---|---|
|
Figure 1 and Table 1 show that MT-Disciplined code that performs no locking has considerable overhead when compared with Unsafe code. If the test is performed twice (once before locking and once again before unlocking), the overhead is 56% - 72% for intel, 29% - 59% for sparc and 43% - 51% for powerpc. If the test is made only once, the overhead is 22% - 33% for intel, 6% - 13% for sparc and 25% - 34% for powerpc.
In a less trivial example (with more activity between locking and unlocking), the overhead as a percentage would be lower. This example demonstrates the worst case in which the cost of each test is comparable with the cost of the unsafe data access itself. Clearly, it is faster to perform the test only once (but this can lead to code duplication and hence less maintainability).
In absolute terms, the overhead is less than 10ns for intel and sparc and 30ns for powerpc. Whether or not this is acceptable depends on the application. If profiling determines that MT-Disciplined code is the bottleneck, it may be necessary to use an Unsafe version instead (as described in the previous section).
| Figure 2 - Mutex Locking |
|---|
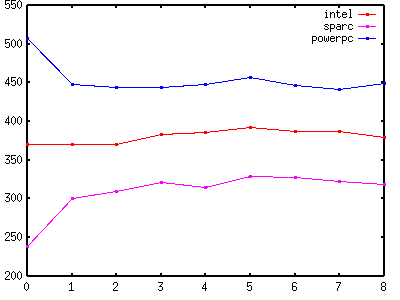 |
| Table 2 - Mutex Locking | ||||||||
|---|---|---|---|---|---|---|---|---|
|
Figure 2 and Table 2 show how hard it is to make predictions when you turn on optimisation. MT-Disciplined code that performs mutex locking incurs an overhead of 27% - 38% (63ns - 91ns) on sparc, only 0% - 6% (0ns - 22ns) on intel, and on powerpc is actually faster by -65ns - -50ns (-13% - -10%).
It's not clear what statements can be made about the overhead of MT-Disciplined code that performs mutex locking when compared with MT-Safe code that performs mutex locking. Sometimes it's slower. Sometimes it's about the same. Sometimes it's faster.
What is clear is that in this case, whether or not the test is performed once or twice doesn't make any difference. This could be because locking a mutex takes much longer than performing the tests for a non-null pointer. It could also just be because the second test was optimised out of existence.
| Figure 3 - Read Locking |
|---|
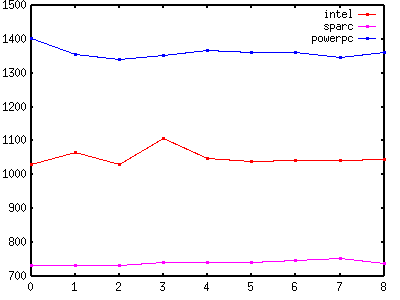 |
| Table 3 - Read Locking | ||||||||
|---|---|---|---|---|---|---|---|---|
|
Figure 3 and Table 3 show that MT-Disciplined code that performs read locking costs about the same as MT-Safe code that performs read locking. The overhead is 0ns - 78ns (0% - 7.6%) on intel (only 0ns - 17ns (0% - 1.7%) if you exclude methods 1 and 3), -1ns - 20ns (-0.1% - 2.7%) on sparc, and -63ns - -41ns (-4.5% - -2.9%) on powerpc.
Further Reading
[Schmidt 1999] presents a treatment of the issues from a C++ perspective.
Conclusions
The traditional approach to thread synchronisation results in software libraries that are not generally reusable. There is either a single hard coded synchronisation strategy, or no synchronisation at all. The flexibility and reusability of software libraries with respect to thread synchronisation can be greatly enhanced by employing the discipline and method architecture. Decoupling the synchronisation strategy from the library makes it possible for the client application, and even the end user, to determine and specify the most appropriate synchronisation strategy to be used by the library.
The ability to use a mixture of synchronisation strategies throughout an application can result in reductions in overhead when compared with a traditional MT-Safe library with a hard coded synchronisation strategy. The overhead incurred by MT-Disciplined code varies depending on the platform and the type of lock used. For readers/writer locks, the overhead is negligible on all platforms tested. For mutex locks, the overhead is noticeable on Sparc but negligible on Intel and PowerPC. For no locks, the overhead is noticeable on all platforms tested. The overhead for no locks can be eliminated when necessary by using alternative non-locking versions of library functions.
References
| [Vo 2000] |
The Discipline and Method Architecture for Reusable Libraries Kiem-Phong Vo Software - Practice & Experience, v.30, pp.107-128, 2000 http://www.research.att.com/sw/tools/sfio/dm-spe.ps |
| [Mattis 1995] |
libglib Peter Mattis, Spencer Kimball and Josh MacDonald http://www.gtk.org/ |
| [raf 2000] |
libslack raf https://libslack.org/ |
| [Schmidt 1999] |
Strategized Locking, Thread-safe Interface and Scoped Locking: Patterns and Idioms for Simplifying Multi-threaded C++ Components Douglas C. Schmidt C++ Report, SIGS, Vol. 11, No. 9, September 1999 http://www.cs.wustl.edu/~schmidt/PDF/locking-patterns.pdf |